
rpc框架-mercury

目录
Mercury is a Remote Procedure Call (RPC) framework specifically designed for use in High-Performance Computing (HPC) systems with high-performance fabrics.
Objective & comparision
- Objective: Create a
reusable RPC libraryfor use in HPC that can serve as a basis for services such asstorage systems,I/O forwarding,analysis frameworksand other forms ofinter-application communication - 优势:
- takes advantage of low-level HPC network fabrics and facilitates the development of user-level data services
- provide reliable RPC functionality, support large data arguments, and take advantage of the HPC network fabrics.
- Mercury remains as thin as possible in order to allow for reusability between various service components that must support different needs.
- how one can enhance RPC to (1)
leverage RDMA-capable networks; (2) supportnode-local service scaling and leverage multi-core processors; (3) enableflexible, node-local deployment scenarios and service composition; (4)bridge nodes between multiple HPC networks; (5) enablefault tolerance.
- Comparision:
- Do not support
efficient large data transfers or asynchronous calls - Can potentially introduce a lot of jitter (extra threads / memory used / etc)
- Mostly built on top of TCP/IP protocols
- Need support for
native transport - Need to be easy to port to new systems
- Need support for
- Do not support
HPC network support
- leverage low-level vendor APIs such as InfiniBandTM Verbs, IntelR Performance Scaled Messaging 2 (PSM2), and CrayR Generic Network Interface (GNI) by y using OFI libfabric [16] as the intermediate layer that abstracts RDMA capabilities for RDMA-capable networks or emulated RMA (over point-to-point) for noncapable networks.

Multi-Core Architecture Support
- by either distributing the load of incoming RPCs across cores or by running multiple services co-located within the same node.
- Communication frameworks typically adopt one of two progress models: either explicit or implicit.
- Explicit progress implies that the user will regularly make progress calls to effectively check into network completion queues, poll file descriptors, etc.
- an implicit progress model will make progress in background without any need for the user to be involved.
decouple the RPC execution activities from the network progress activities, which leads us to actually adopt a progress-and-trigger model that gives services more control over the placement of the progress and execution threads.Scalable endpoints allow for sharing a single endpoint resources between threads by assigning separate transmit and receive contexts (including completion queues) to each thread.When SEPs are used, context switches between threads no longer exist— a fundamental advantage for RPC multi-core architectures. todo? SEP 原理介绍
Flexible Provisioning and Topology
Transparent Node-Local Deployment
When deploying data services, it is common for some of these services to either issue RPCs to other local services (i.e., separate processes within the same node) or to send RPCs back to themselves (i.e., within the same process). todo? 没看懂这句话
issue RPCs to other local service
- Mercury 可以通过检测目标地址在同一个节点上来透明地使用共享内存。
- 使用
无锁共享环形缓冲区和无锁队列,可以以非常低的延迟实现无锁传输。 - 对于批量数据传输并防止任何中间 memcpy,可以使用 Linux Cross-Memory Attach 机制实现零拷贝传输(即从源缓冲区到目标缓冲区的一个单一和直接复制)
send RPCs back to themselves
- Mercury 检测目标地址何时与源地址相同,并使用相同的参数打包机制发送 RPC
- 方法是立即将 RPC 排队到本地完成队列中,在内部发出完成信号以唤醒任何在进度调用中等待的潜在线程。
- 批量数据传输是通过源缓冲区和目标缓冲区之间的 memcpy 实现的。
Service Composition
- 为了提供灵活的组合,RPC API 不能特定于任何实现,而只能依赖于源和目标概念。然后可以一致地使用 RPC 机制在不同的服务“服务器”和“客户端”之间进行通信。
- 使用代理模式,或者硬件支持的 SEP 模式

Resilience and Fault Tolerance
- 允许服务在发生故障(例如,节点故障、服务组件无响应)后恢复,而不会影响性能,只需为取消挂起的操作提供强大的支持,
回收 RPC 操作先前分配的本地资源并从故障中正常恢复。 - 如果涉及的任何对等方不再响应,则 RPC 和批量数据传输操作都可能被中断,在这种情况下,必须取消挂起的操作。取消无法完成的操作,无论是因为发生了故障还是达到了超时,对于达到正确的完成都是必要的。

Function
- function arguments / metadata transferred with RPC request
- two-sides model with unexpected /expected messaging (todo? 含义)
- Message size limited to a few kilobytes (low-latency)
- Bulk data transferred using separate and dedicated API
- one-sided model that exposes RMA semantics (high-bandwidth)
- Network Abstraction layer
- alows definition of multiple network plugins
- MPI and BMI plugins first plugins
- shared-memory plugin(mmap+CMA, supported on Cray w/CLE6)
- CCI plugin contributed by ORNL
- Libfabric plugin contributed by Intel

Architecture
- the network abstraction layer, which provides a high-performance communication interface on top of lower level network fabrics.
- the RPC layer, which provides users with the necessary components for sending and receiving RPC metadata (small messages). This includes serialization and deserialization of function arguments;
- the bulk layer, which provides the necessary components for handling large arguments—this implies large data transfers through RMA;
- the (optional) high-level RPC layer, which aims at providing a convenience API, builds on top of the lower layers and provides macros for generating RPC stubs as well as serialization and deserialization functions.



Network Abstraction Layer
- The NA layer uses a plugin mechanism so that support for various network protocols can be easily added and selected at runtime.
- NA provides a minimal set of function calls that abstract the underlying network fabric and that can be used to provide: target address lookup, point-to-point messaging with both unexpected and expected messaging, remote memory access (RMA), progress and cancelation.
- The API is non-blocking and uses a callback mechanism so that upper layers can provide asynchronous execution more easily
// info_string 表示使用 network plugin种类,listen表示是否是target
na_class_t * NA_Initialize(const char *info_string, na_bool_t listen);
na_class_t *NA_Initialize_opt(const char *info_string, na_bool_t listen,const struct na_init_info *na_init_info);
// release na_class_t object
na_return_tNA_Finalize(na_class_t *na_class);
//a context within this plugin must be created, which internally creates and associates a completion queue for the operations
na_context_t *NA_Context_create(na_class_t *na_class);
na_return_t NA_Context_destroy(na_class_t *na_class, na_context_t *context);
//Target Address Lookup
na_return_t NA_Addr_self(na_class_t *na_class, na_addr_t *addr);
//convert that address to a string
na_return_t NA_Addr_to_string(na_class_t *na_class, char *buf, na_size_t buf_size, na_addr_t addr);
//string can then be exchanged to other processes through out-of-band mechanisms (e.g., using a file, etc), which can then look up the target
na_return_t NA_Addr_lookup(na_class_t *na_class, const char *name, na_addr_t *addr);
na_return_t NA_Addr_free(na_class_t *na_class, na_addr_t addr);
- Point-to-point Messaging
na_return_t
NA_Msg_send_unexpected(na_class_t *na_class, na_context_t *context,na_cb_t callback, void *arg, const void *buf, na_size_t buf_size,void *plugin_data, na_addr_t dest_addr, na_uint8_t dest_id, na_tag_t tag,na_op_id_t *op_id);
na_return_t
NA_Msg_send_expected(na_class_t *na_class, na_context_t *context,
na_cb_t callback, void *arg, const void *buf, na_size_t buf_size,void *plugin_data, na_addr_t dest_addr, na_uint8_t dest_id, na_tag_t tag,na_op_id_t *op_id);
na_return_t
NA_Msg_recv_unexpected(na_class_t *na_class, na_context_t *context,
na_cb_t callback, void *arg, void *buf, na_size_t buf_size,
void *plugin_data, na_op_id_t *op_id);
na_return_t
NA_Msg_recv_expected(na_class_t *na_class, na_context_t *context,
na_cb_t callback, void *arg, void *buf, na_size_t buf_size,
void *plugin_data, na_addr_t source_addr, na_uint8_t source_id,
na_tag_t tag, na_op_id_t *op_id);
- Remote Memory Access
na_return_t
NA_Mem_handle_create(na_class_t *na_class, void *buf, na_size_t buf_size,unsigned long flags, na_mem_handle_t *mem_handle);
na_return_t
NA_Mem_register(na_class_t *na_class, na_mem_handle_t mem_handle);
- serialise /deserialize
na_return_t
NA_Mem_handle_serialize(na_class_t *na_class, void *buf, na_size_t buf_size,na_mem_handle_t mem_handle);
na_return_t
NA_Mem_handle_deserialize(na_class_t *na_class, na_mem_handle_t *mem_handle,const void *buf, na_size_t buf_size);
na_return_t
NA_Put(na_class_t *na_class, na_context_t *context, na_cb_t callback, void *arg,
na_mem_handle_t local_mem_handle, na_offset_t local_offset,
na_mem_handle_t remote_mem_handle, na_offset_t remote_offset,
na_size_t data_size, na_addr_t remote_addr, na_uint8_t remote_id, na_op_id_t *op_id);
na_return_t
NA_Get(na_class_t *na_class, na_context_t *context, na_cb_t callback, void *arg,
na_mem_handle_t local_mem_handle, na_offset_t local_offset,
na_mem_handle_t remote_mem_handle, na_offset_t remote_offset,
na_size_t data_size, na_addr_t remote_addr, na_uint8_t remote_id, na_op_id_t *op_id);
- Progress and Cancelation
当调用 progress 时,一旦操作完成或已经在完成队列中,它就会返回,以便可以调用 NA_Trigger() 来清空队列并执行用户回调。
na_return_t
NA_Progress(na_class_t *na_class, na_context_t *context, unsigned int timeout);
na_return_t
NA_Trigger(na_context_t *context, unsigned int timeout, unsigned int max_count,int callback_ret[], unsigned int *actual_count);
na_return_t
NA_Cancel(na_class_t *na_class, na_context_t *context, na_op_id_t *op_id);
Mercury RPC Layer
- the HG interface provides the following primitives:
target address lookup, RPC registration, RPC execution, progress and cancelation.
initialization
hg_class_t *
HG_Init(const char *info_string, hg_bool_t listen);
hg_return_t
HG_Finalize(hg_class_t *hg_class);
hg_context_t *
HG_Context_create(hg_class_t *hg_class);
hg_return_t
HG_Context_destroy(hg_context_t *context);
Registration
- 在这里注册具体函数名字,和对应的执行函数rpc_cb
typedef hg_return_t (*hg_proc_cb_t)(hg_proc_t proc, void *data);
typedef hg_return_t (*hg_rpc_cb_t)(hg_handle_t handle);
hg_id_t
HG_Register_name(hg_class_t *hg_class, const char *func_name,
hg_proc_cb_t in_proc_cb, hg_proc_cb_t out_proc_cb,
hg_rpc_cb_t rpc_cb);
hg_return_t
HG_Registered_disable_response(hg_class_t *hg_class, hg_id_t id, hg_bool_t disable);
hg_return_t
HG_Deregister(hg_class_t *hg_class, hg_id_t id);
Target Address Lookup
hg_return_t
HG_Addr_self(hg_class_t *hg_class, hg_addr_t *addr);
hg_return_t
HG_Addr_to_string(hg_class_t *hg_class, char *buf, hg_size_t *buf_size, hg_addr_t addr);
hg_return_t
HG_Addr_lookup(hg_class_t *hg_class, const char *name, hg_addr_t *addr);
hg_return_t
HG_Addr_free(hg_class_t *hg_class, hg_addr_t addr);
Execution-origin
//Using the RPC ID defined after a call to HG_Register(), one can use the HG_Create() call to define a new hg_handle_t object that can be used (and later re-used without reallocating resources) to set/get input/output arguments.
hg_return_t
HG_Create(hg_context_t *context, hg_addr_t addr, hg_id_t id, hg_handle_t *handle);
//pack the input arguments within a structure, for which a serialization function is provided with the HG_Register() call. The HG_Forward() function can then be used to send that structure (which describes the input arguments). This function is non-blocking. When it completes, the associated callback can be executed by calling HG_Trigger().
typedef hg_return_t (*hg_cb_t)(const struct hg_cb_info *callback_info);
hg_return_t
HG_Forward(hg_handle_t handle, hg_cb_t callback, void *arg, void *in_struct);
//When HG_Forward() completes (i.e., when the user callback can be triggered), the RPC has been remotely executed and a response with the output results has been sent back.
hg_return_t
HG_Get_output(hg_handle_t handle, void *out_struct);
hg_return_t
HG_Free_output(hg_handle_t handle, void *out_struct);
hg_return_t
HG_Destroy(hg_handle_t handle);
Execution-target
- 在 HG_Respond 函数中:This call is also non-blocking. When it completes, the associated callback is placed onto a completion queue. It can then be triggered after a call to
HG_Trigger().
//On the target, the RPC callback function passed to the HG_Register() call must be defined.
typedef hg_return_t (*hg_rpc_cb_t)(hg_handle_t handle);
//Whenever a new RPC is received, that callback will be invoked.
hg_return_t
HG_Get_input(hg_handle_t handle, void *in_struct);
//When the input has been retrieved, the arguments contained in the input structure can be passed to the actual function call. When the execution is done, an output structure can be filled with the return value and/or the output arguments of the function.
typedef hg_return_t (*hg_cb_t)(const struct hg_cb_info *callback_info);
hg_return_t
HG_Respond(hg_handle_t handle, hg_cb_t callback, void *arg, void *out_struct);
hg_return_t
HG_Free_input(hg_handle_t handle, void *in_struct);
Progress &Cancelation
//Mercury uses a callback model. Callbacks are passed to non-blocking functions and are pushed to the context's completion queue when the operation completes.
hg_return_t
HG_Progress(hg_context_t *context, unsigned int timeout);
//When an operation completes, calling HG_Trigger() allows the callback execution to be separately controlled from the main progress loop.
hg_return_t
HG_Trigger(hg_context_t *context, unsigned int timeout,
unsigned int max_count, unsigned int *actual_count);
hg_return_t
HG_Cancel(hg_handle_t handle);
Mercury Bulk Layer
bulk descriptor
hg_return_t
HG_Bulk_create(hg_class_t *hg_class, hg_uint32_t count,
void **buf_ptrs, const hg_size_t *buf_sizes,
hg_uint8_t flags, hg_bulk_t *handle);
hg_return_t HG_Bulk_free(hg_bulk_t handle);
//memory pointers from an existing bulk descriptor can be accessed with:
hg_return_t
HG_Bulk_access(hg_bulk_t handle, hg_size_t offset, hg_size_t size,
hg_uint8_t flags, hg_uint32_t max_count, void **buf_ptrs,
hg_size_t *buf_sizes, hg_uint32_t *actual_count);
//通过 HG_Bulk_bind() 函数将源地址绑定到批量句柄,代价是序列化和反序列化寻址信息的额外开销。仅当从 HG_Get_info() 调用检索的源地址与必须用于传输的源地址不同(例如,多个源)时,才需要这样做。
hg_return_t
HG_Bulk_bind(hg_bulk_t handle, hg_context_t *context);
hg_addr_t
HG_Bulk_get_addr(hg_bulk_t handle);
Serialization
hg_return_t
hg_proc_hg_bulk_t(hg_proc_t proc, void *data);
Bulk Transfer
hg_return_t
HG_Bulk_transfer(hg_context_t *context, hg_bulk_cb_t callback, void *arg,
hg_bulk_op_t op, hg_addr_t origin_addr,
hg_bulk_t origin_handle, hg_size_t origin_offset,
hg_bulk_t local_handle, hg_size_t local_offset,
hg_size_t size, hg_op_id_t *op_id);
struct hg_info {
hg_class_t *hg_class; /* HG class */
hg_context_t *context; /* HG context */
hg_addr_t addr; /* HG address */
hg_id_t id; /* RPC ID */
};
struct hg_info *
HG_Get_info(hg_handle_t handle);
Mercury Serialization Macros
Mercury 提供的宏可以减少发送 RPC 调用所需的代码量。 Mercury 没有使用繁琐的 RPC 存根和代码生成器,而是使用 Boost 预处理器库,以便用户可以生成序列化和反序列化函数参数所需的所有样板代码。
MERCURY_REGISTER(hg_class, func_name, in_struct_type_name, out_struct_type_name, rpc_cb);
相关使用案例–Mochi

- 其他: DAOS / DeltaFS / UnifyCR / Dataspaces / ParaView / Visit / SOS / Faodel
RPC 执行流程
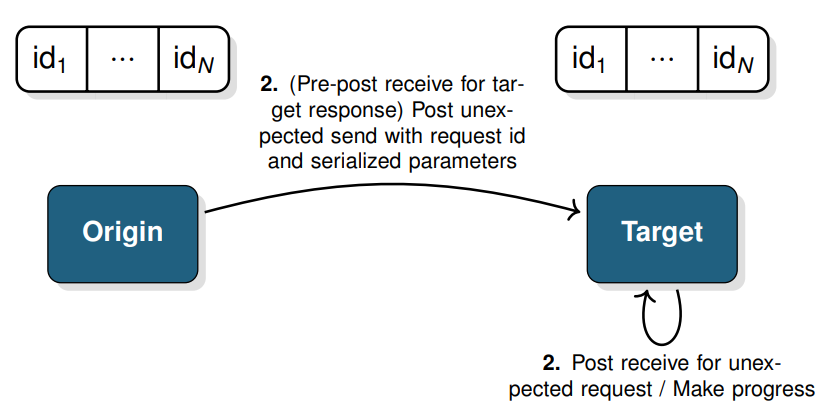
- define the mechanism to send an RPC reqeust (ignore response or not)
- origin & target: register call and get request id
- origin: (pre-post recieve for target response) post unexpected send with request id and serialized parameters; target: Post receive for unexpected request/ make progress
- target: execute call
- target: post send with serialized response; Origin: make
progess
Progress Model
callback-based model with completion queue- explicit progress with
HG_Progress() and HG_Trigger()- allows user to create workflow
- no need to have an explicit wait call (shim layers possible)
- facilitate operation scheduling, multi-threaded execution and cancellation
do {
unsigned int actual_count = 0;
do {
ret = HG_Trigger(context, 0, 1, &actual_count);
} while ((ret == HG_SUCCESS) && actual_count);
if (done)
break;
ret = HG_Progress(context, HG_MAX_IDLE_TIME);
} while (ret == HG_SUCCESS);

RPC 代码
.1. 客户端代码
open_in_t in_struct;
/* Initialize the interface and get target address */
hg_class = HG_Init("ofi+tcp://eth0:22222", HG_FALSE);
hg_context = HG_Context_create(hg_class);
[...]
HG_Addr_lookup_wait(hg_context, target_name, &target_addr);
/* Register RPC call */
rpc_id = MERCURY_REGISTER(hg_class, "open", open_in_t, open_out_t);
/* Set input parameters */
in_struct.in_param0 = in_param0;
/* Create RPC request */
HG_Create(hg_context, target_addr, rpc_id, &hg_handle);
/* Send RPC request */
HG_Forward(hg_handle, rpc_done_cb, &rpc_done_args, &in_struct);
/* Make progress */
/* cancellation */
// Cancellation: HG Cancel() on handle
// Callback still triggered (canceled = completion)
.2. 回调函数
hg_return_t
rpc_done_cb(const struct hg_cb_info *callback_info)
{
open_out_t out_struct;
/* Get output */
HG_Get_output(callback_info->handle, &out_struct);
/* Get output parameters */
ret = out_struct.ret;
out_param0 = out_struct.out_param0;
/* Free output */
HG_Free_output(callback_info->handle, &out_struct);
return HG_SUCCESS;
}
.3. 服务端代码
- 客户端和服务端代码基本一致,HG_Init(“ofi+tcp://eth0:22222”, HG_TRUE); TRUE 表示是服务端
int main(int argc, void *argv[])
{
/* Initialize the interface and listen */
hg_class = HG_Init("ofi+tcp://eth0:22222", HG_TRUE);
[...]
/* Register RPC call */
MERCURY_REGISTER(hg_class, "open", open_in_t, open_out_t, open_rpc_cb);
/* Make progress */
[...]
/* Finalize the interface */
[...]
}
.4. 打开回调函数
hg_return_t open_rpc_cb(hg_handle_t handle)
{
open_in_t in_struct;
open_out_t out_struct;
/* Get input */
HG_Get_input(handle, &in_struct);
in_param0 = in_struct.in_param0;
/* Execute call */
out_param0 = open(in_param0, ...);
/* Set output */
open_out_struct.out_param0 = out_param0;
/* Send response back to origin */
HG_Respond(handle, NULL, NULL, &out_struct);
/* Free input and destroy handle */
HG_Free_input(handle, &in_struct);
HG_Destroy(handle);
return HG_SUCCESS;
}
Bulk Data Transfers
Transfercontrolled by target (better flow control)Memory buffer(s)abstracted by handle- Handle must be serialized and exchanged using other means

- 客户端代码
/* Initialize the interface and get target address */
[...]
/* Create bulk handle (only change) */
HG_Bulk_create(hg_info->hg_bulk_class, 1, &buf, &buf_size, HG_BULK_READ_ONLY, &bulk_handle);
/* Attach bulk handle to input parameters */
[...]
in_struct.bulk_handle = bulk_handle;
/* Create RPC request */
HG_Create(hg_context, target_addr, rpc_id, &hg_handle);
/* Send RPC request */
HG_Forward(hg_handle, rpc_done_cb, &rpc_done_args, &in_struct);
/* Make progress */
- 服务端代码
/* Get input parameters and bulk handle */
HG_Get_input(handle, &in_struct);
[...]
origin_bulk_handle = in_struct.bulk_handle;
/* Get size of data and allocate buffer */
nbytes = HG_Bulk_get_size(bulk_handle);
/* Create block handle to read data */
HG_Bulk_create(hg_info->hg_bulk_class, 1, NULL, &nbytes,
HG_BULK_READWRITE, &local_bulk_handle);
/* Start pulling bulk data (execute call / send response in callback) */
HG_Bulk_transfer(hg_info->bulk_context, bulk_transfer_cb,
bulk_args, HG_BULK_PULL, hg_info->addr, origin_bulk_handle, 0,
local_bulk_handle, 0, nbytes, HG_OP_ID_IGNORE);
Non contiguous memory bulk
- allows for scatter/gather memory transfers using virtual memory offsets and length
hg_return_t HG_Bulk_create(
hg_bulk_class_t *hg_bulk_class,
hg_size_t count,
void **buf_ptrs,
const hg_size_t *buf_sizes,
hg_uint8_t flags,
hg_bulk_t *handle
);
Macros
- generate as much boilerplate code as possible for
- serialization/deserialization of parameters
- sending/executing rpc
- single include
header file sharedbetween origin and target - make use of boost preprocessor for macro definition
- generate serialization / deserialization functions and structure that contains parameters.

Resource
- https://mercury-hpc.github.io/assets/publications/2016-07-14-Intel-meeting.pdf
- https://mercury-hpc.github.io/assets/publications/2017-06-22-Nersc_slides.pdf
- https://mercury-hpc.github.io/assets/publications/SC18_BOF_Intro_mercury.pdf
- http://sites.computer.org/debull/A20mar/p23.pdf
- https://mercury-hpc.github.io/user/hg_macros/
- 案例代码:https://github1s.com/mercury-hpc/mercury/blob/HEAD/src/mercury_core.c#L5056
- 案例代码:https://mochi.readthedocs.io/en/latest/mercury/05_bulk.html